学习ret2csu
ret2csu
在 ELF 可执行文件中,程序初始化时会自动调用 __libc_csu_init(),里面包含两段特别“肥”的 gadget,称为:
- 第一段 gadget:设置寄存器
- 第二段 gadget:执行函数调用
这两个 gadget 非常适合构造任意函数调用(带多个参数)。
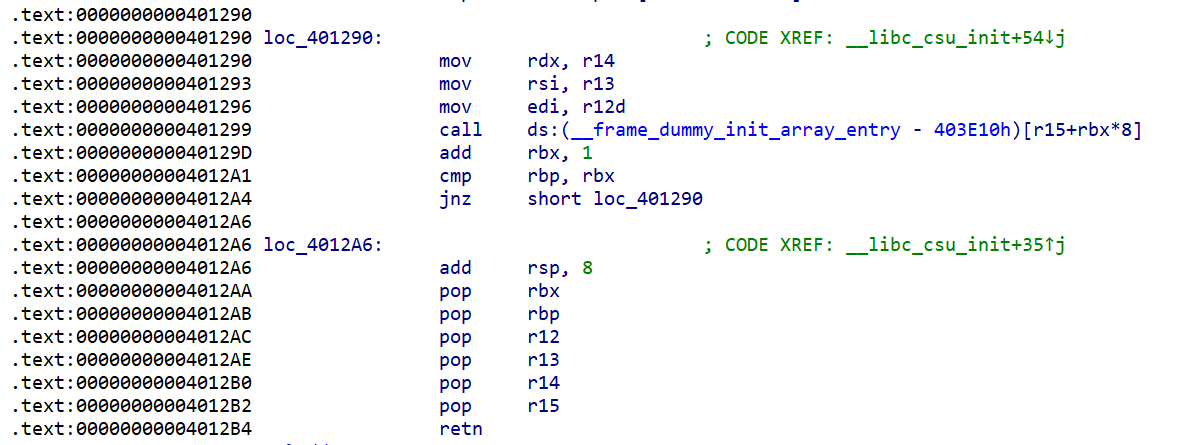
gadget1(设置寄存器的 gadget)
通常长这样(来自 _libc_csu_init):
1 | 0x40122a: ; gadget1 |
gadget2(执行 call 的 gadget)
1 | 0x401210: ; gadget2 |
注意:gadget2 的mov 指令后面的 参数设置 (如:rdx,r13)并不固定,不要盲目套用ROP
比如这道题[HNCTF 2022 WEEK2]ret2csu的__libc_csu_init(),接下来都以它为例子。
在 ret2csu 技巧中,我们可以间接控制 6 个关键寄存器,从而设定函数调用所需的参数,并跳转至任意函数。
它的核心就是:利用程序中 .init 段的两段特殊 gadget,构造出一次受控的函数调用。
具体而言,可控的寄存器包括:
rbx、rbp、r12、r13、r14、r15(通过“pop”指令控制)- 最终可影响的参数寄存器有:
rdi(由r12 赋值)、rsi(由r13 赋值)、rdx(由r14 赋值)
此外,还能执行一次由[r15 + rbx*8] 解析出的地址的call 操作。
通常,我们将:
rbx 设置为0rbp 设置为1
这样在执行 call qword ptr [r15 + rbx*8] 时,实际就变成了 call [r15],只需将 r15 设置为指向目标函数地址的地址(如 GOT 表项),而无需关心 rbx 的偏移。
由于 add rbx, 1; cmp rbx, rbp; jnz ... 这段逻辑会在 rbx != rbp 时跳回循环开头,而我们往往是从那里返回过来的,不希望再次跳转,因此设置 rbx = 0 和 rbp = 1,可以确保跳转被跳过,正常执行目标函数。
如果无法获得目标函数的 GOT 表项,可以选择调用某个空函数(如 _term_proc),只需将 r15 设置为指向该空函数地址的地址即可,利用这个 call 实现寄存器设置的副作用。
需要注意:r12 的值最终传给的是 edi(也就是 rdi 的低 4 字节),高位自动填 0,因此用 ret2csu 给 rdi 传递完整地址是不可行的,只适合传递整数或小范围地址。
[HNCTF 2022 WEEK2]ret2csu
让我们先来欣赏一下 一个简单的 ret2csu 的源代码
ret2csu.c
1 | #include<stdio.h> |
用 ida进行 反编译以后的代码
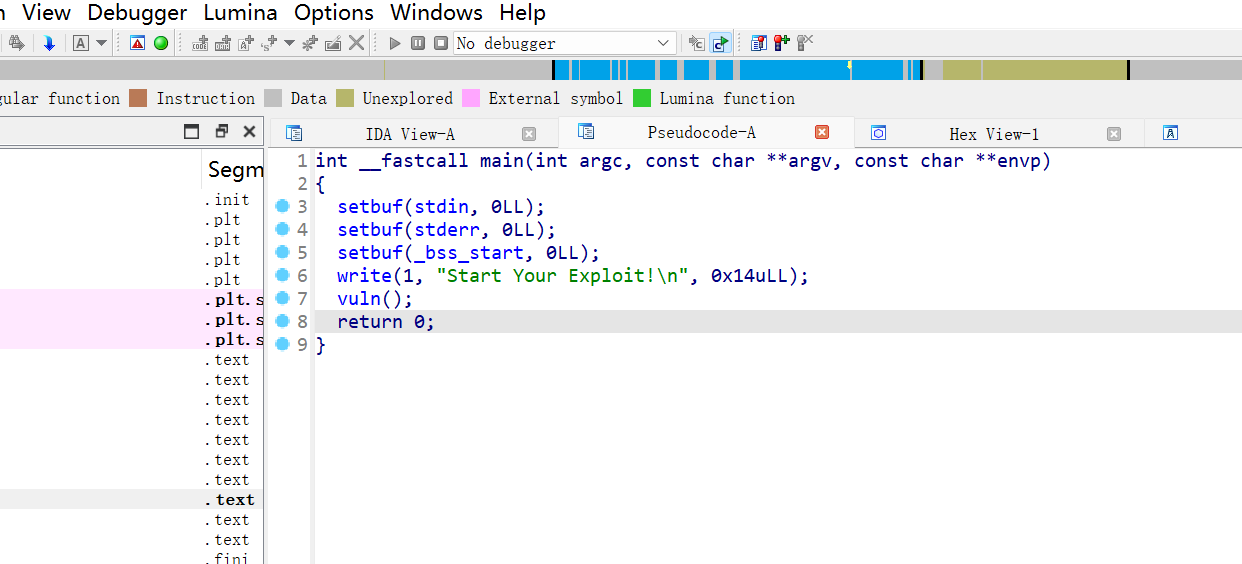
在vuln()函数 发现栈溢出点,无后门函数
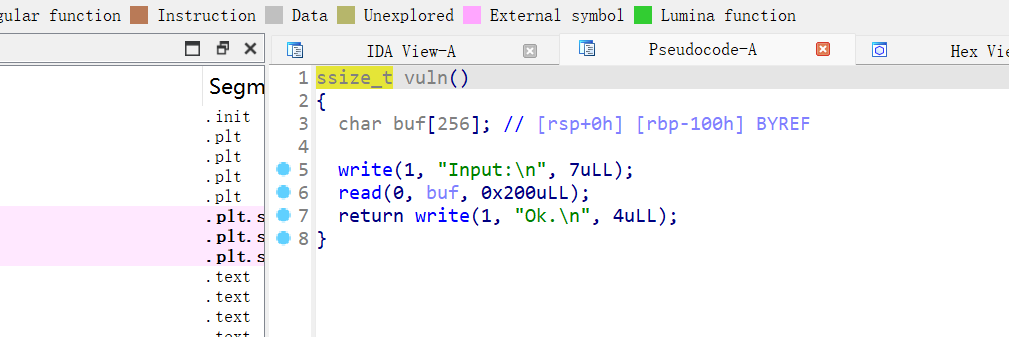
保护机制也开得很少
这道题选择 ret2csu 的打法就是
- 利用栈溢出执行 libc_csu_gadgets 获取 write 函数地址,并使得程序重新执行 main 函数
- 从libc文件中获取 system 函数地址和/bin/sh字符串
- 再次利用栈溢出执行 libc_csu_gadgets 执行 system(‘/bin/sh’) 获取 shell。
就是利用这两个gadget版块
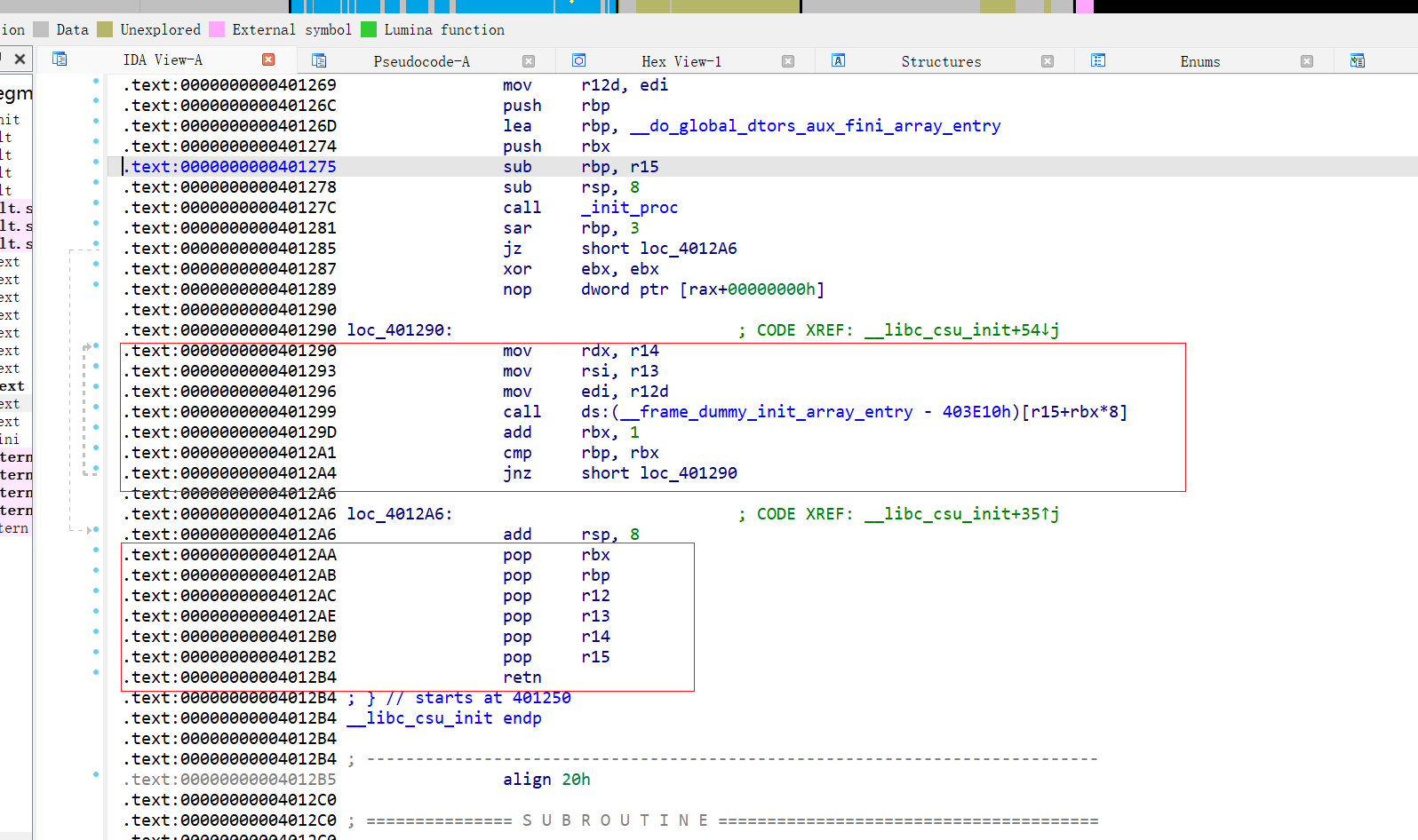
一个 gadget板块 ,我叫做 A_csu
| 0x4012AA | pop rbx | 将 Rsp指向的 栈顶元素弹出,给 rbx寄存器,栈帧减去 8 个字节 |
|---|---|---|
| 0x4012AB | pop rbp | 将 Rsp指向的 栈顶元素弹出,给 rbp 寄存器,栈帧减去 8 个字节 |
| 0x4012AC | pop r12 | 将 Rsp指向的 栈顶元素弹出,给 r12 寄存器,栈帧减去 8 个字节 |
| 0x4012AE | pop r13 | 将 Rsp指向的 栈顶元素弹出,给 r13 寄存器,栈帧减去 8 个字节 |
| 0x4012B0 | pop r14 | 将 Rsp指向的 栈顶元素弹出,给 r14 寄存器,栈帧减去 8 个字节 |
| 0x4012B2 | pop r15 | 将 Rsp指向的 栈顶元素弹出,给 r15 寄存器,栈帧减去 8 个字节 |
| 0x4012B4 | retn |
另一个 gadget板块 ,我叫做 B_csu
| 0x401290 | mov rdx, r14 | 将 r14 中的值给 rdx |
|---|---|---|
| 0x401293 | mov rsi, r13 | 将 r13 中的值给 rsi |
| 0x401296 | mov edi, r12d | 将 r12 中的值给 edi |
| 0x401299 | call ds:(__frame_dummy_init_array_entry - 403E10h)[r15+rbx*8] | 调用 函数 [r15 + rbx8](调用的是 [r15 + rbx8]这个地址 ,指向的函数地址) |
| 0x40129D | add rbx, 1 | rbx + 1 |
| 0x4012A1 | cmp rbp, rbx | 比较 rbp 和 rbx里的值,是否相等 |
| 0x4012A4 | jnz short loc_401290 | 不相等就跳转到 0x401290,重复执行 |
由于程序给的函数 很少
想要得到一个函数地址 ,来泄露 libc的地址,就可以选择 调用 write() 来打印 write()的地址 ,即 write_got(这是 write()在 GOT表的地址 ,write_got这个地址里存着 write()的真实地址)
既然想要调用函数 ,就得提前给别人(函数)把参数设置好,人家(函数)才肯帮你做事,发挥它的作用
想成功 调用 write(),就需先设置好 write()所需的参数,那这道题的源码举例
1 | write(1,"Input:\n",7); |
write()会用到 三个参数 ,也就是 rdi,rsi,rdx这三个寄存器里的值
其函数原型如下
1 | ssize_t write(int fd, const void *buf, size_t count); |
1.
fd:文件描述符(int 类型)
表示你要写入的目标,可以是标准输出、文件、socket 等。
常见的标准文件描述符有:
0:标准输入(stdin)-
1 :标准输出(stdout)2:标准错误输出(stderr)在例子中,
fd = 1,表示将内容写到终端(标准输出) 。
2.
buf:缓冲区指针(const void * 类型)
指向你要写入的数据。
在例子中,
buf = "Ok.\n",这是一个 C 风格的字符串,实际内容是:
2
3
4
字符 ‘k’ (0x6b)
字符 ‘.’ (0x2e)
字符 换行 '\n' (0x0a)注意:虽然是字符串,但
write 不依赖字符串结尾的\0,它只根据count 决定写入多少字节。
3.
count:写入字节数(size_t 类型)
- 指定你要写入的字节数。
- 在例子中,
count = 4,表示写入"Ok.\n" 的前 4 个字符。
所以如果 我们的目标是 调用 write()打印 write_got里的write()的真实地址
那就要控制 rdi (作为一参)为 1( 表示将内容写到终端(标准输出) ,rsi(作为二参)为 write_got(可以理解为一个指向 write()地址的指针),rdx(作为三参)为要写入的字节数
1 | from pwn import * |
这里的b'a'*(0x38)是为了 栈对齐,当我们执行完A_csu后,返回到 B_csu ,会向下继续执行A_csu
1 | payload += b'a'*(0x38) + p64(vuln) |
add rsp, 8 → 跳过 1 个元素(8 字节)- 后面
pop 掉 6 个寄存器 → 共 6 × 8 = 0x30 字节 - 总共:
8 + 0x30 = 0x38 字节
也就是说, A_csu 执行完之后,总共清理了 0x38 字节的栈空间(我们这里是在 “应付” 第二次 A_csu)
如果你不提前用一些 junk 数据(如 b'a' * 0x38)来占位,它就会从你的真实 ROP 链中“吃掉”内容,导致运行错误。
b'a'*(0x38):喂给第二个 A_csu 的用的数据,防止 ROP 崩坏;
这就是一种“恢复现场”的方式
最后要记录的是自己犯的一个错误
这道题我的本地打不通,但远端能打通,C0trick师傅说是因为我本地与远端的libc不同,刚开始不理解,我天真的以为脚本有加载题目给的 libc,libc = ELF("./libc.so.6"),就是本地与远端的libc就相同了🤣
只能说没学懂之前还觉得自己有道理,晓得为什么后,真的会被自己之前的想法蠢笑😂
题目附件的程序在本地运行时,连接的 libc库是本地的libc,而不是题目附件给的 libc
而调用 ELF("./libc.so.6") 后,会:
- 加载指定的 libc 文件里的信息;
- 自动分析里面的
.sym 符号表(如函数名和偏移); - 提供接口查找函数偏移(如
libc.sym['system']、libc.got['read']); - 可以用于泄露地址后,计算 libc 基址 + 某函数偏移 = 实际函数地址。
并不会修改 本地附件程序所连接的 libc
那要如何修改本地附件程序所连接的 libc呢?
patchelf 与glibc-all-in-one 配合使用,可以用于更改 elf 文件 libc 版本
(加油!尽管也许自己现在真的很蠢,但是搞明白了问题以后你正在一点点变得强大)
 wechat
wechat




